 TrailDB 0.6 Released! See the highlights of the latest TrailDB release.
TrailDB 0.6 Released! See the highlights of the latest TrailDB release.
Maximize Speed
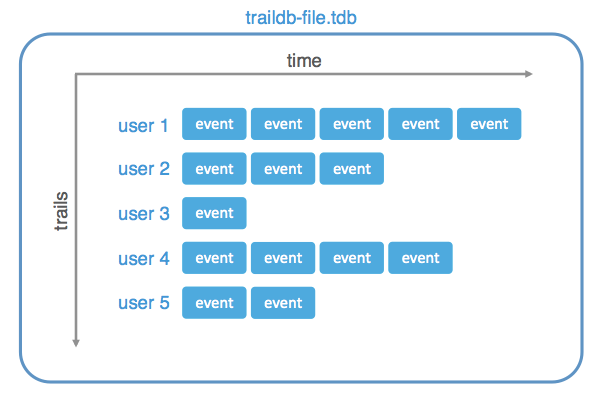
TrailDB is a library, implemented in C, which allows you to query series of events at blazing speed. TrailDB is also optimized for speed of development: Use its simple API with your favorite language, in your favorite environment.
Minimize Space
TrailDB's secret sauce is data compression. It leverages predictability of time-based data to compress your data to a fraction of its original size. In contrast to traditional compression, you can query the encoded data directly, decompressing only the parts you need.
Use Cases
TrailDB was created at AdRoll to power processing of time-series of events. You can use it, for instance, to
- Compute metrics, such as the bounce rate
- Analyze usage patterns
- Detect anomalies
- Cluster and predict user behavior
Since 2014, AdRoll has used TrailDB to store and query over tens of trillions events originating from the web.
Feature Highlights
- High performance: Process millions of events per second on a single core
- High compression ratio: Comparable to Gzip
- Scalable: Capacity of your server is the limit
- Immutable: Easy to handle with distributed architectures
- Reliable: Over 90% test coverage
- Simple API: Easy to use
 C
C
 Python
Python
 Go
Go
 R
R
 Haskell
Haskell
 D
D
Getting Started
The quickest way to get started is to install TrailDB and go through the TrailDB tutorial. If you want to learn more about the motivation for TrailDB, read a blog post about TrailDB open-sourcing, watch the Introduction to TrailDB on Youtube and browse the slides of the presentation here.
If you have questions, you can find us on TrailDB channel at Gitter. Contributions are welcome!