This tutorial expects that you have TrailDB installed and working. If you haven’t installed TrailDB yet, see Getting Started for instructions.
Part I: Create a simple TrailDB¶
In this example, we will create a tiny TrailDB that includes events from three users. You can find the full Python source code in the traildb-python repo and the C source in the main traildb repo.
Note that opening a new TrailDB constructor fails if there is an
existing TrailDB with the same name. If you run this example multiple
times, you should delete the tiny directory, which may contain partial
results, and tiny.tdb before running the example.
First, let’s create a new constructor that we will use to populate the TrailDB.
The TrailDB will have two fields, username and action, which we will specify
when creating the constructor.
from traildb import TrailDBConstructor, TrailDB
from uuid import uuid4
from datetime import datetime
cons = TrailDBConstructor('tiny', ['username', 'action'])
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <traildb.h>
int main(int argc, char **argv)
{
const char *fields[] = {"username", "action"};
tdb_error err;
tdb_cons* cons = tdb_cons_init();
if ((err = tdb_cons_open(cons, "tiny", fields, 2))){
printf("Opening TrailDB constructor failed: %s\n", tdb_error_str(err));
exit(1);
}
Now we can populate the TrailDB with events. We are going
to create three dummy users, each of which will have three
events. Note that the primary key identifying the user is a
UUID. We can use the uuid module
in Python to generate UUIDs, or you can create your own identifiers like
the C code does.
for i in range(3):
uuid = uuid4().hex
username = 'user%d' % i
for day, action in enumerate(['open', 'save', 'close']):
cons.add(uuid, datetime(2016, i + 1, day + 1), (username, action))
static char username[6];
static uint8_t uuid[16];
const char *EVENTS[] = {"open", "save", "close"};
uint32_t i, j;
/* create three users */
for (i = 0; i < 3; i++){
memcpy(uuid, &i, 4);
sprintf(username, "user%d", i);
/* every user has three events */
for (j = 0; j < 3; j++){
const char *values[] = {username, EVENTS[j]};
uint64_t lengths[] = {strlen(username), strlen(EVENTS[j])};
/* generate a dummy timestamp */
uint64_t timestamp = i * 10 + j;
if ((err = tdb_cons_add(cons, uuid, timestamp, values, lengths))){
printf("Adding an event failed: %s\n", tdb_error_str(err));
exit(1);
}
}
}
Once you are done adding events in the TrailDB, you have to finalize it. Finalization takes care of compacting the events and creating a valid TrailDB file.
cons.finalize()
if ((err = tdb_cons_finalize(cons))){
printf("Closing TrailDB constructor failed: %s\n", tdb_error_str(err));
exit(1);
}
tdb_cons_close(cons);
You can check the contents of the new TrailDB using the tdb tool by
running tdb dump -i tiny. We can easily print out its contents using
the API too:
for uuid, trail in TrailDB('tiny').trails():
print uuid, list(trail)
tdb* db = tdb_init();
if ((err = tdb_open(db, "tiny"))){
printf("Opening TrailDB failed: %s\n", tdb_error_str(err));
exit(1);
}
tdb_cursor *cursor = tdb_cursor_new(db);
/* loop over all trails */
for (i = 0; i < tdb_num_trails(db); i++){
const tdb_event *event;
uint8_t hexuuid[32];
tdb_uuid_hex(tdb_get_uuid(db, i), hexuuid);
printf("%.32s ", hexuuid);
tdb_get_trail(cursor, i);
/* loop over all events of this trail */
while ((event = tdb_cursor_next(cursor))){
printf("[ timestamp=%llu", event->timestamp);
for (j = 0; j < event->num_items; j++){
uint64_t len;
const char *val = tdb_get_item_value(db, event->items[j], &len);
printf(" %s=%.*s", fields[j], len, val);
}
printf(" ] ");
}
printf("\n");
}
That’s it! You can easily extend this example for creating TrailDBs based on event sources of your own.
Part II: Analyze a large TrailDB of Wikipedia edits¶
Wikipedia provides a database dump of the full edit history of Wikipedia pages. This is a treasure trove of data that can be used to analyze, for instance, behavior of individual contributors or edit history of individual pages.
We converted the 50GB compressed dump to a TrailDB. For this tutorial, you should download the pre-made TrailDB. Two versions are provided:
-
wikipedia-history.tdb contains the full edit history of Wikipedia between January 2001 and May 2016. This TrailDB contains trails for 44M contributors, covering 663M edit actions. The size of the file is 5.8GB.
-
wikipedia-history-small.tdb contains a random sample of 1% contributors (103MB). If you are curious, this script was used to produce a random extract of the full TrailDB.
First, you should download the smaller snapshot above,
wikipedia-history-small.tdb, which allows you to verify quickly
that the code works. Python is convenient for small and medium-scale
analysis but it tends to be slow with larger amounts of data. For
analyzing the full wikipedia-history.tdb, we recommend that you use C,
D, Go or Haskell bindings of TrailDB.
Number of sessions by contributor¶
Trails in the Wikipedia TrailDBs include all edit actions
of each Wikipedia contributor. Contributors include both anonymous
contributors who are identified by the IP address (field ip) and
registered contributors who have a username (field user). Each
event includes also a title of the page that was edited and the
timestamp of the edit action.
To measure contributor activity, it is useful to count the number of edit sessions, in addition to the raw number of edits. We define a session as a sequence of actions where actions are at most 30 minutes apart, similar to how sessions are defined in web analytics. Counting the number of sessions by contributor is easy with TrailDB.
You can find the full Python source code in the traildb-python repo and the C source in the main traildb repo.
def sessions(tdb):
for i, (uuid, trail) in enumerate(tdb.trails(only_timestamp=True)):
prev_time = trail.next()
num_events = 1
num_sessions = 1
for timestamp in trail:
if timestamp - prev_time > SESSION_LIMIT:
num_sessions += 1
prev_time = timestamp
num_events += 1
print 'Trail[%d] Number of Sessions: %d Number of Events: %d' %\
(i, num_sessions, num_events)
tdb_cursor *cursor = tdb_cursor_new(db);
uint64_t i;
for (i = 0; i < tdb_num_trails(db); i++){
const tdb_event *event;
tdb_get_trail(cursor, i);
event = tdb_cursor_next(cursor);
uint64_t prev_time = event->timestamp;
uint64_t num_sessions = 1;
uint64_t num_events = 1;
while ((event = tdb_cursor_next(cursor))){
if (event->timestamp - prev_time > SESSION_LIMIT)
++num_sessions;
prev_time = event->timestamp;
++num_events;
}
printf("Trail[%llu] Number of Sessions: %llu Number of Events: %llu\n",
i,
num_sessions,
num_events);
}
The code loops over all trails and measures the time between actions.
If the time exceeds 30 minutes, we increment the session counter. Note
that the Python code sets only_timestamp=True which makes the cursor
return only timestamps instead of the full events. This is a performance
optimization that removes unnecessary allocations in the inner loop
which are particularly expensive in Python.
The code outputs the number of sessions and the number of events for each contributor. We can plot a histogram of the results:
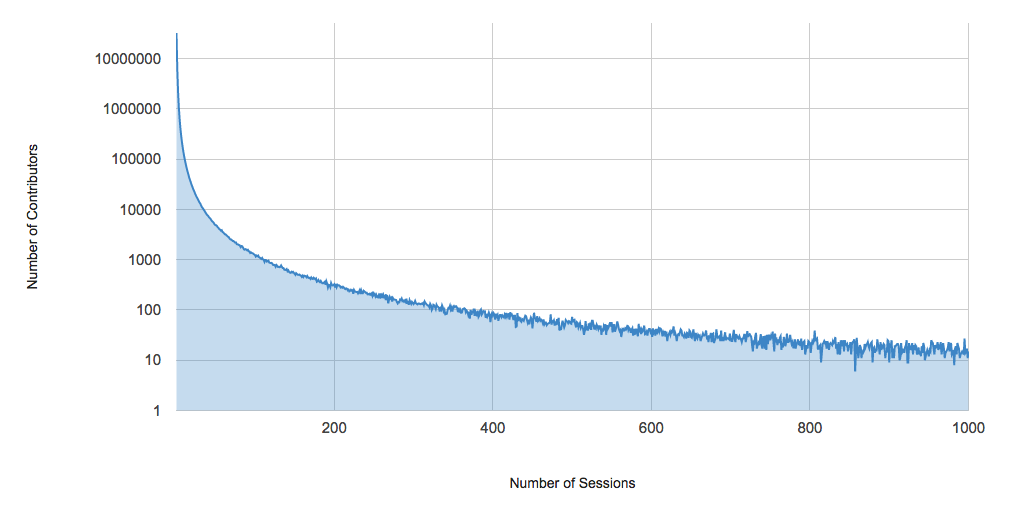
Unsurprisingly, the vast majority of contributors have only one session. However, there is a very long tail of contributors who have over 200 sessions.
Not all contributors are human beings. There are a number of benevolent
bots making routine edits in Wikipedia, such as maintaining basic
statistics. In fact, in wikipedia-history.tdb you can find over 4500
users whose name ends with bot. As a fun follow up exercise, you
can write a script that tries to detect bots based on their behavior
that is often very characteristic and easy to distinguish from human
contributors.