Data Model¶
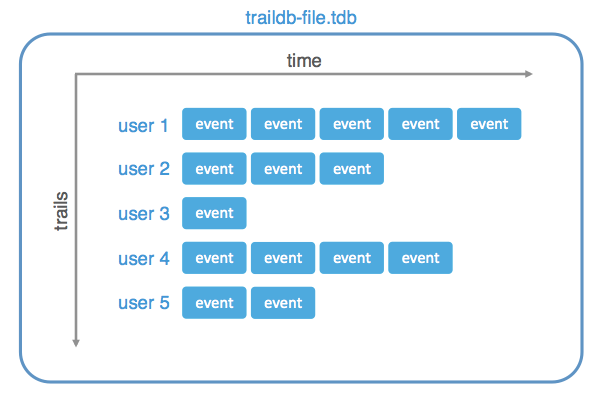
- traildb
-
- TrailDB is a collection of trails.
- trail
-
- A trail is identified by a user-defined 128-bit UUID as well as an automatically assigned trail ID.
- A trail consists of a sequence of events, ordered by time.
- event
-
- An event corresponds to an event in time, related to an UUID.
- An event has a 64-bit integer timestamp.
- An event consists of a pre-defined set of fields.
- field
-
- Each TrailDB follows a schema that is a list of fields.
- A field consists of a set of values.
In a relational database, UUID would be the primary key, event would be a row, and fields would be the columns.
The combination of a field ID and a value of the field is represented as an item in the C API. Items are encoded as 64-bit integers, so they can be manipulated efficiently. See Working with items, fields, and values for detailed API documentation.
Performance Best Practices¶
Constructing a TrailDB is more expensive than reading it¶
Constructing a new TrailDB consumes CPU, memory, and temporary disk space roughly O(N) amount where N is the amount of raw data. It is typical to separate the relatively expensive construction phase from processing so enough resources can be dedicated to it.
Use tdb_cons_append for merging TrailDBs¶
In some cases it makes sense to construct smaller TrailDB
shards and later merge them to larger TrailDBs using the
tdb_cons_append() function. Using this
function is more efficient than looping over an existing TrailDB and
creating a new one using tdb_cons_add().
Mapping strings to items is a relatively slow O(L) operation¶
Mapping a string to an item using tdb_get_item()
is an O(L) operation where L is the number of distinct values in
the field. The inverse operation, mapping an item to a string using
tdb_get_item_value() is a fast O(1)
operation.
Mapping an UUID to a trail ID is a relatively fast O(log N) operation¶
Mapping an UUID to a trail ID using
tdb_get_trail_id() is a relatively fast O(log
N) operation where N is the number of trails. The inverse operation,
mapping a trail ID to UUID using tdb_get_uuid() is
a fast O(1) operation.
Use multiple tdb handles for thread-safety¶
A tdb handle returned by tdb_init() is not
thread-safe. You need to call tdb_init() and
tdb_open() in each thread separately. The good news
is that these operations are very cheap and data is shared, so the
memory overhead is negligible.
Cursors are cheap¶
Cursors are cheap to create with tdb_cursor_new().
The only overhead is a small internal lookahead buffer whose size can be
controlled with the TDB_OPT_CURSOR_EVENT_BUFFER_SIZE option, if you need
to maintain a very large number of parallel cursors.
TrailDBs larger than the available RAM¶
A typical situation is that you have a large amount of SSD (disk) space compared to the amount of available RAM. If the size of the TrailDBs you need to process exceeds the amount of RAM, performance may suffer or you may need to complicate the application logic by opening only a subset of TrailDBs at once.
An alternative solution is to open all TrailDBs using
tdb_open() as usual, which doesn’t consume much memory
per se, process some of the data, and then tag inactive TrailDBs with
tdb_dontneed() which signals to the operating
system that the memory can be paged. When TrailDBs are needed again, you
can call tdb_willneed().
A benefit of this approach compared to opening and closing TrailDBs explicitly is that all cursors, pointers etc. stay valid, so they can be kept in memory without complex resource management.
Conserve memory with 32-bit items¶
A core concept in the TrailDB API is an item, represented by a 64-bit
integer. You can use these items in your own application, outside
TrailDB, to make data structures simpler and processing faster, compared
to using strings. Only when really needed, you can convert items back to
strings using e.g. tdb_get_item_value().
If your application stores and processes a very large number of
items, you can cut the memory consumption potentially by 50%
by using 32-bit items instead of the standard 64-bit items.
TrailDB makes this operation seamless and free: You can call the
tdb_item_is32() macro to make sure the item is
safe to cast to uint32_t – if the result is yes, you can cast the
item to uint32_t and use them transparently in place of the 64-bit
items.
Finding distinct values efficiently in a trail¶
Sometimes you are only interested in distinct values of a trail,
e.g. the set of pages visited by a user. Since trails may contain
many duplicate items, which are not interesting in this case, you
can speed up processing by setting TDB_OPT_ONLY_DIFF_ITEMS with
tdb_set_opt() which makes the cursor remove most
of the duplicates.
Since this operation is based on the internal compression scheme, it is not fully accurate. You still want to construct a proper set structure in your application but this option can make populating the set much faster.
Return a subset of events with event filters¶
Event filters are a powerful feature for querying a subset of events in trails. Event filters support boolean queries over fields, expressed in conjunctive normal form. For instance, you could query certain web browsing events with
action=page_view AND (page=pricing OR page=about)
First, you need to construct a query using
tdb_event_filter_add_term,
which adds terms to OR clauses, and
tdb_event_filter_new_clause which adds
a new clause that is connected by AND to the previous clauses.
Once the filter has been constructed, you can apply it to a cursor with
tdb_cursor_set_event_filter(). After
this, the cursor returns only events that match the query. Internally,
the cursor still needs to evaluate every event but filters may speed up
processing by discarding unwanted events on the fly.
Note that the tdb_event_filter handle needs to be available as long
as you keep using the cursor. You can use the same filter in multiple
cursors.
If you want to use the same filter in all cursors, call
tdb_set_opt with the key TDB_OPT_EVENT_FILTER.
This makes sure that all cursors created with this TrailDB
handle will get the filter applied. You can still override the filter
at the cursor level with tdb_cursor_set_event_filter().
In effect, this defines a view to TrailDB. See also the entry below about materialized views.
Whitelist or blacklist trails (a view over a subset of trails)¶
A special case of event filters, introduced above, are filters that match all events or no events. These filters are most commonly used to make TrailDB return only a subset of trails.
To whitelist a subset of trails, do the following: First disable
all trails using tdb_event_filter_new_match_none().
Then enable selected trails with tdb_event_filter_new_match_all(). Here is an example:
struct tdb_event_filter *empty = tdb_event_filter_new_match_none();
struct tdb_event_filter *all = tdb_event_filter_new_match_all();
tdb_opt_value value = {.ptr = empty};
/* first blacklist all */
tdb_set_opt(db, TDB_OPT_EVENT_FILTER, value);
/* then whitelist selected trails */
value.ptr = all;
for (i = 0; i < num_selected; i++)
tdb_set_trail_opt(db,
trail_ids[i],
TDB_OPT_EVENT_FILTER,
value);
If you want to blacklist a subset of trails instead, you can just call
tdb_set_trail_opt with an empty filter.
A benefit of this approach that empty and all are optimized internally so
that no events will be evaluated for trails that have these filters enabled.
You can use these filters to extract a new TrailDB that contains only a subset
of trails from the source TrailDB, as described below.
Create TrailDB extracts (materialized views)¶
It is possible to extract a subset of events from an existing TrailDB to a new TrailDB. A benefit of doing this is that the new TrailDB is smaller than the original, which can make queries faster.
To create an extract (a materialized view), open an existing TrailDB
as usual. Create an event filter that defines the
subset of events, and set it to the TrailDB handle with
tdb_set_opt using the key TDB_OPT_EVENT_FILTER.
Now you can create the extract by calling tdb_cons_open() as usual, followed by tdb_cons_append() using the TrailDB handle initialized above. The tdb_cons_append() function will add only events matching with the filter to the new TrailDB.
You can also create materialized views on the command line with
the tdb merge command.
Join trails over multiple TrailDBs¶
It is a common pattern to shard TrailDBs by time, e.g. by day. Now if you want to return the full trail of a user over K days, you need to handle each of the K TrailDBs separately.
Multi-cursors provide a convenient way to stich together trails in multiple (or a single) TrailDB(s). You need to initialize the cursors for each of the K TrailDBs as usual, pass them to a multi-cursor instance, and use the multi-cursor to iterate over a joined trail seamlessly.
Multi-cursors work even if the underlying cursors are overlapping in
time since they perform an efficient O(Kn) merge sort on the fly.
Note that you can also apply event filters to the underlying cursors to
produce a joined trail over a subset of events.
Limits¶
- Maximum number of trails: 259 - 1
- Maximum number of events in a trail: 250 - 1
- Maximum number of distinct values in a field: 240 - 2
- Maximum number of fields: 16,382
- Maximum size of a value: 258 bytes
Internals¶
TrailDB uses a number of different compression methods to minimize the amount of space used. In contrast to the usual approach of compressing a file for storage, and decompressing it for processing, TrailDB compresses the data when TrailDB is constructed but it never decompresses all the data again. Only the parts that are actually requested, using a lazy cursor, are decompressed on the fly. This makes TrailDB cache-friendly and hence fast to query.
The data model of TrailDB enables efficient compression: Since events are grouped by UUID, which typically corresponds a user, a server, or other such logical entity, events within a trail tend to be somewhat predictable - each logical entity tends to behave in its own characteristic way. We can leverage this by only encoding every change in behavior, similar to run-length encoding.
Another observation is that since in the TrailDB data model events are always sorted by time, we can utilize delta-encoding to compress 64-bit timestamps that otherwise would end up consuming a non-trivial amount of space.
After these baseline transformations, we can observe that the distribution of values is typically very skewed: Some items are way more frequent than others. We also analyze the distribution of pairs of values (bigrams) for similar skewedness. The skewed, low-entropy distributions of values can be efficiently encoded using Huffman coding. Fields that are not good candidates for entropy encoding are encoded using simpler variable-length integers.
The end result is often comparable to compressing the data using Zip. The big benefit of TrailDB compared to Zip is that each trail can be decoded individually efficiently and the output of decoding is kept in an efficient integer-based format. By design, the TrailDB API encourages the use of integer-based items instead of original strings for further processing, making it easy to build high-performance applications on top of TrailDB.